Streaming Kafka Ingest
This page describes how to read data from Kafka and visualize it in a kdb Insights View.
Apache Kafka is an event streaming platform that seamlessly integrates with kdb Insights Enterprise, enabling real-time data processing through pipelines connected to Kafka data sources. For this example, we have provided a Kafka subway feed that generates live alerts for NYC Subway trains, including arrival times, station coordinates, direction, and route details.
This example shows how to use the CLI to do the following:
-
Download the package containing the pipeline and view.
-
Deploy the package to read subway data from Kafka, decode the data using a JSON decoder, and write the data to the
subwaysubscriber. -
View data in the web interface.
-
Check progress of the running pipeline.
-
Teardown a previously installed version of the package.
Before you begin, you must complete the prerequisites described in the following section.
Note
Streaming subway data
Refer to the Streaming subway data to a data grid in Views walkthrough for instructions on setting up and deploying a package to ingest and view Kafka data using the web interface.
Prerequisites
-
Configure a username and bearer token, for the KX Downloads Portal, as environment variables. To do this:
-
Click the KX Downloads Portal link and follow the steps to login.
-
Click your login name, in the top right-hand corner, and click Token Management.
-
Click Add New Token.
-
Copy the value in the Bearer field and save it for use later.
-
Use the following commands to set the environment variables, where
KX_USERis the username you used to login to the KX Downloads Portal, andKX_DL_BEARERis the bearer token you just generated.bash
Copyexport KX_USER=<USERNAME>
export KX_DL_BEARER=<TOKEN>
-
-
A running kdb Insights Enterprise system with the hostname URL configured as the value for the
KX_HOSTNAMEenvironment variable.bash
Copyexport KX_HOSTNAME=<URL>
-
The CLI configured for your deployment with authentication credentials
Downloading the package
-
Run the following command to set
KX_VERSIONenvironment variable in your terminal.bash
Copyexport KX_VERSION=<VERSION>
-
Download the sample package with the command below.
bash
Copycurl -s --fail-with-body -D /dev/stderr -u ${KX_USER}:${KX_DL_BEARER} -L -OJ https://portal.dl.kx.com/assets/raw/package-samples/${KX_VERSION}/kafka-ingest-${KX_VERSION}.kxi
-
Run the following command to unpack and view the contents of the kafka-ingest sample package.
bash
Copyexport PKG=kafka-ingest
kxi package unpack $PKG-$KX_VERSION.kxi
The
kafka-ingestsample package contains the files listed below and described in the following table:bash
Copykafka-ingest/
├── manifest.yaml
├── pipelines
│ └── subway.yaml
├── src
│ ├── ml.py
│ ├── ml.q
│ ├── subway.py
│ └── subway.q
└── views
└── subway.yaml
3 directories, 7 files
Artefact
Description
manifest.yamlUsed by the CLI for package management. Do not modify the contents of this file.
pipelinesThe pipeline configuration files,
subway.yaml.srcPipeline spec files.
subway.q: this is default pipeline spec, written in q. This is located underkafka-ingest/src/subway.qin the unpacked package.subway.py: The equivalent Python pipeline spec is located underkafka-ingest/src/subway.py.ml.q/ml.py: ML q and Python examples are also contained within the package for reference.viewsThe view configuration files,
subway.yaml.
Click on the q or Python tab below to view the contents of the q and Python versions of the subway pipeline spec.
q
Python
kafka-ingest/src/subway.q
q
subway: ([] trip_id: `symbol$(); arrival_time: `timestamp$(); stop_id: `symbol$(); stop_sequence: `long$(); stop_name: `symbol$(); stop_lat: `float$(); stop_lon: `float$(); route_id: `long$(); trip_headsign: `symbol$(); direction_id: `symbol$(); route_short_name: `symbol$(); route_long_name: `symbol$(); route_desc: `char$(); route_type: `long$(); route_url: `symbol$(); route_color: `symbol$())
.qsp.run
.qsp.read.fromKafka[.qsp.use (!) . flip (
(`brokers ; "kafka.trykdb.kx.com:443");
(`topic ; "subway");
(`options; (!) . flip (
(`security.protocol ; "SASL_SSL");
(`sasl.username ; "demo");
(`sasl.password ; "demo");
(`sasl.mechanism ; "SCRAM-SHA-512"))))]
.qsp.decode.json[]
.qsp.map[{ enlist x }]
.qsp.transform.schema[subway]
.qsp.write.toSubscriber[`subway;`trip_id]
kafka-ingest/src/subway.py
Python
schema = {'trip_id': pykx.SymbolAtom,
'arrival_time': pykx.TimestampAtom,
'stop_id': pykx.SymbolAtom,
'stop_sequence': pykx.ShortAtom,
'stop_name': pykx.SymbolAtom,
'stop_lat': pykx.FloatAtom,
'stop_lon': pykx.FloatAtom,
'route_id': pykx.ShortAtom,
'trip_headsign': pykx.SymbolAtom,
'direction_id': pykx.SymbolAtom,
'route_short_name': pykx.SymbolAtom,
'route_long_name': pykx.SymbolAtom,
'route_desc': pykx.List,
'route_type': pykx.ShortAtom,
'route_url': pykx.SymbolAtom,
'route_color': pykx.SymbolAtom}
sp.run(sp.read.from_kafka('subway',
brokers='kafka.trykdb.kx.com:443',
options={'sasl.username': 'demo',
'sasl.password': 'demo',
'sasl.mechanism': 'SCRAM-SHA-512',
'security.protocol': 'SASL_SSL'})
| sp.decode.json()
| sp.transform.schema(schema)
| sp.write.to_subscriber('subway', 'trip_id'))
The subway pipeline spec file can be summarised as follows:
|
Object/Node |
q Object |
Python Object |
Description |
|---|---|---|---|
|
Schema |
table |
|
The schema definition used for type conversion when parsing incoming data. |
|
Read from Kafka |
. |
|
Setup Kafka reader with topic, broker and security config. |
|
Decode JSON |
.qsp.decode.json
|
sp.decode.json
|
Use JSON decoder to decode incoming data. |
|
Transform Schema |
.qsp.transform.schema
|
sp.transform.schema
|
Parse the incoming data using the defined schema. |
|
Write to Subscriber |
.qsp.write.toSubscriber
|
sp.write.to_subscribe
|
Write the data to a subscriber named subway with trip_id key column. |
Deploying the package
Next, authenticate with kdb Insights Enterpriseand deploy the package to begin reading the subway data from Kafka and writing it to the subscriber/web-socket.
-
Run the following command to authenticate with kdb Insights Enterprise:
bash
Copykxi auth login
-
Perform the following setup for Python (skip to 3 for q):
-
Run the following command to deploy the package:
bash
Copykxi pm push $PKG
kxi pm deploy $PKG
Note
Cleaning up resources
It may be necessary to teardown any previously installed version of the package and clean up resources before deploying a new version of the package.
Viewing output
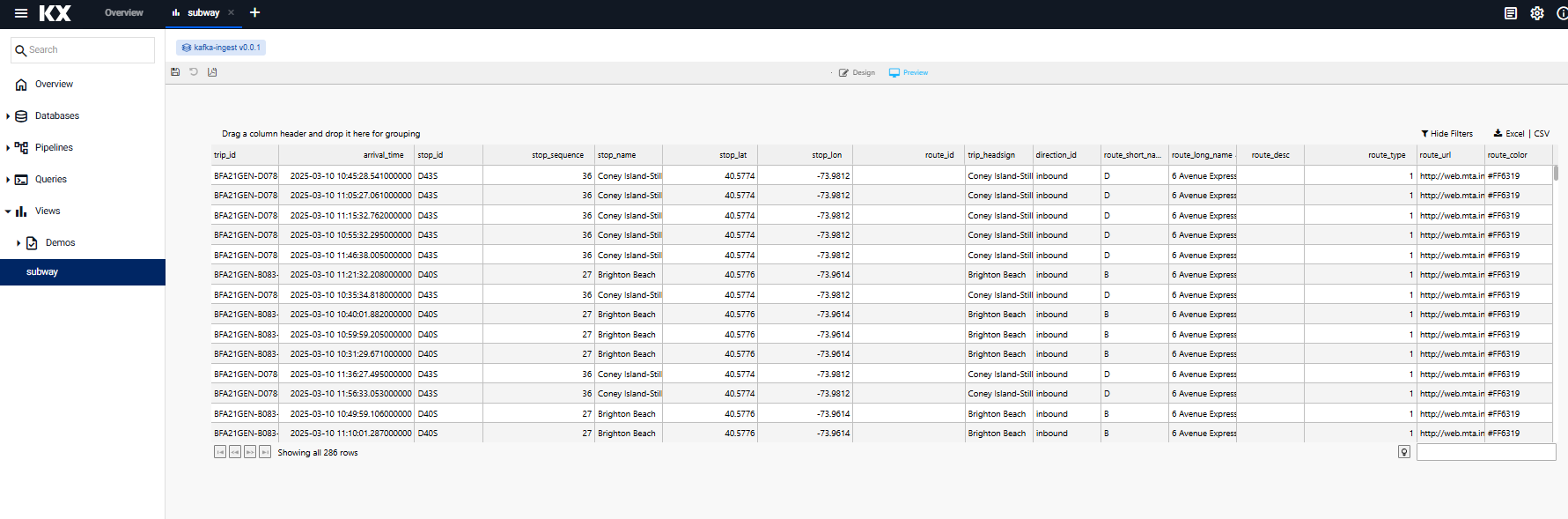
The subway View is included in the kafka-ingest sample package.
To view data for all inbound trains on the 6, 7 or 8th Avenue Express routes:
-
Log into the kdb Insights Enterprise Web Interface
-
Navigate to the Views tab and click on the
subwayView.
Checking progress
To check the progress of the running pipeline, use the kdb Insights Enterprise REST APIs.
-
Get the token generated when you authenticated against the system.
bash
Copyexport KX_TOKEN=$(kxi auth print-token)
Note
Regenerate expired token
If this token expires, you can regenerate it by running
kxi auth loginagain and re-storing with the command above. -
Check the progress of the SP pipeline using the details API, as follows:
bash
Copycurl -H "Authorization: Bearer $KX_TOKEN" ${KX_HOSTNAME}/streamprocessor/details
A pipeline
stateofRUNNINGindicates that it is processing data.bash
Copy[
{
"id":"kafka-ingest-subway",
"name":"subway",
"group":"g-794319749428",
"mode":"default",
"created":"2025-03-03T12:22:29.000000000",
"lastSeen":"2025-03-03T12:27:11.389548559",
"state":"RUNNING",
"error":"",
"metrics":{
"eventRate":0,
"bytesRate":0,
"latency":null,
"inputRate":1328.754,
"outputRate":2.745616
},
"logCounts":{
"trace":0,
"debug":0,
"info":157,
"warn":3,
"error":0,
"fatal":0
},
"packageName":"kafka-ingest",
"reportedMetadata":[
{
"id":1,
"name":"kafka-ingest-subway-1-spwork",
"reportedMetadata":[
{
"operatorID":"subscriber_subway",
"plugin":"subscriber",
"cacheLimit":2000,
"keyCol":"trip_id",
"publishFrequency":null,
"table":"subway"
}
],
"pipeID":"kafka-ingest-subway"
}
]
}
]
Teardown
You must teardown a previously installed version of the package and clean up resources before you can deploy a new version of the package.
-
To teardown packages and their resources, run the command below.
bash
Copykxi pm teardown --rm-data $PKG